The previous post in this series established a non-technical basis for understanding data lakes and why they might be important. In this post, the focus will be on providing a more technical take on data lakes. This will not be a detailed technical primer so much as a review of the architectural dynamics that underly data lakes and some of their implications.
This post is intended for a more technical audience that understands the basics of distributed computing, is somewhat familiar with modern cloud infrastructure offerings, and has some background in managing data for analytics or building application databases.
OVERVIEW
To some extent, data lakes are a happy accident born out of the availability distributed storage solutions and distributed computing capacity on commodity hardware, and helped along by the mainstreaming of the cloud. The Apache Hadoop project enabled scalability and variety in analytics that would have previously been impossible and the advent of cloud services like AWS made it possible to experiment with these tools without an enormous capital outlay up front.
Once these innovations took hold, a supporting infrastructure for analytics that delivers greater scalability and flexibility was a natural outcome.
The emergence of data lakes affords us the opportunity to rethink the architectural model for supporting analytics in enterprises. We can collectively elevate our game and address some of the flaws in previous generations of analytics architectures like data warehouses.
This post focuses on defining the data lake from a more technical perspective, describing the benefits, identify the technology components that power data lakes, and providing some guidance on how to get started with implementation.
A TECHNICAL DEFINITION OF THE DATA LAKE
The basic working definition established in the previous blog post in this series still holds. Data lakes are central repositories of data pulled together for the purpose of analysis. Data lakes provide a number of benefits including better collaboration, more consistent results, greater scalability, and the ability to run a more diverse set of analyses combining both traditional BI style rollup and drill down with more advanced AI and ML techniques.
From a technical perspective data lakes are defined by a few characteristics of their architecture:
- Low cost, scalable storage – Cloud-based object stores and distributed file systems change the dynamics of storing large amounts of data for analytics. These systems tend to be very durable, scale horizontally, and be relatively low cost compared to using a dedicated on-premise array to store similar volumes of information. Raw data can now be retained indefinitely making it easier to reproduce analyses, correct errors, and back test models.
- Compute independent of storage – Compute and storage are somewhat decoupled in this architecture. This allows each one to scale independently providing better efficiency of resource utilization and the ability to vary computing resources based on the task at hand (e.g., using GPUs for deep learning while use conventional CPUs for other analyses).
- Schema on read vs. schema on write – The schema structure for the data is applied when it is read or more broadly the representation of the data for analytics independent of storage format. A specific storage format is not required for data to be accessible. Data can be treated in the way that is most convenient for analysis and stored in the way that makes the most operational sense.
These three elements when brought together enable unprecedented flexibility to the analytics environment.
BENEFITS OF THE DATA ARCHITECTURE
As data lakes have matured, the strengths of the architecture have become more apparent, and we can lean into those strengths by adding the right tooling and taking the right broad, architectural approach. Some of the key benefits of the data lake architecture include:
- Reuse and Collaboration – Data lakes can be an asset that is leveraged across the organization for analytics. Analytics can become collaborative over a data set with common semantics explored and processed using common tooling.
- Improved Governance – Data lakes create a point of control for governance. Data that is centralized can be secured and monitored. Consistent, global policies for data can be imposed. This has to be balanced against giving teams enough autonomy for creative exploration and innovation.
- Agility – By allowing data to the more flexibly integrated and allowing many data types to be integrated from internal and external sources in one place. Support for diverse workloads further enables a more agile approach to analytics.
- Scalability – This new model fundamentally changes the game in terms of the scalability of computation. Petabyte-scale computation is within reach for a much broader set of companies and terabyte-scale computations have gone from a monumental technical challenge to routine part of everyday analysis.
- Cost Efficiency – Because storage and compute are decoupled, they can be scaled independently. Compute capacity can be added and removed as needed rather than being tied to its underlying storage mechanism. Bulky raw data can be stored in relatively low-cost cloud storage.
ARCHITECTURE PRINCIPLES
Realizing these benefits starts with observing a few key principles that stem from the underlying foundations of data lakes and can help guide your approach.
The architecture should be thought of holistically – Older approaches to building architectures for analytics like data warehouses have had a strict separation between the platform used to analyze the data and the tools used to extract, transform, and load (ETL) the data. With data lakes, analysis, ingestion, and data preparation often happening in the same broad architecture.
This can create a more integrated experience for users and provides a richer understanding of the data, its lineage, and how it evolves over time. Beyond providing storage for the data, the data lake can be thought of as a computing fabric for the integration and processing of the data.
Management and governance tools are important – As mentioned in the previous post, without a shared catalog, security controls, and common tools for data management, the lake can quickly devolve into a messy shared file system. While some of the scalability benefits of the lake can still be achieved even without tight management, most of the benefits related to reuse, collaboration, and leveraging the investment in the lake will not be realized without a well-developed management layer.
Take full advantage of the capabilities of the cloud – As alluded to above, the cloud is an enabler that helps make data lakes practical for a broader swath of organizations. Leveraging the capabilities of cloud providers to both spin up clusters on demand and store data without having to configure a complex distributed file system makes building a lake much easier. Unless you have access to substantial resources and strict requirements preventing you from using the public cloud, building a lake on premises is not advisable.
UNDERSTANDING THE TECHNOLOGY STACK
While the high level discussion above is useful in creating a mental model around data lakes, it is important to at least start to dig into the technology to get a concrete understanding.
The first step in defining an architecture for your organization in a more detailed way is understanding the full scope of the data lake technology stack. This section lays out the “bill of materials” for the data lake at a high-level as a starting point.
The figure below illustrates the components that exist in each layer of the architecture.
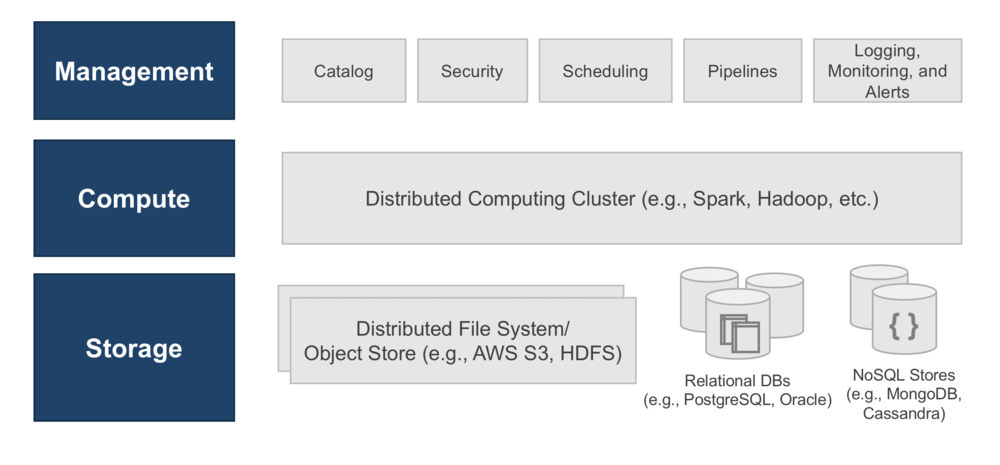
The table below describes these components in more detail and lays out some of the potential technologies that can be used to support them.
| Layer | Component | Description | Examples |
|---|---|---|---|
| Management | Catalog and Metadata Management | The data lake needs a comprehensive catalog of the data it contains so that users can find the information they need and to power other parts of the infrastructure like security and data lineage. | Hive Metastore, Database System Tables, Proprietary Tools (e.g., Alation) |
| Security | There must also be a means to secure the information. This includes the network security of the supporting infrastructure, server level security, and authentication and access control for interacting with information. | Kerberos, Cloud Provider Tools, OS-level Security | |
| Scheduling | Tools for triggering scheduled jobs and managing dependencies across multiple jobs. | Cron, Apache Airflow, ETL Tool-specific | |
| Pipelines | Integrated tooling defining and executing repeatable jobs for data integration and ETL operations is essential to having a cohesive, usable data model within the lake. | Commercial ETL Tools, Custom Dev, Last Generation Big Data Tools (Sqoop, Pig), Cloud Provider Tools (e.g., Amazon Glue), Streaming (e.g., Kafka) | |
| Logging, Monitoring, and Alerts | Understanding the state of the data lake and the details of activity within it are an important part of creating a secure, reliable environment. | Linux System Tools, Cloud Provider Tools, Platform Logs (e.g., Apache Spark Logging) | |
| Compute | Distributed Computing Framework | As described above, using a compute layer that is independent of storage adds increased flexibility to address a broader range of use cases. | Hadoop Map Reduce, Apache Spark, Proprietary ETL Tools, Proprietary Data Science Platforms |
| Storage | Distributed File System/ Object Store | The core of the data lake is often a distributed file system or object. The use of a storage layer that operates independent of the compute layer further reinforces the flexibility of the lake. | Hadoop Distributed File System (HDFS), Cloud Storage (e.g., AWS S3) |
| Relational Databases | Relational databases also have a role to play in the data lake. In many cases, they are sources or targets for data integration and transformation pipelines within the Lake. More specialized databases optimized to perform well under analytics workload may even be used directly as a components of data lake storage. | AWS Redshift, Snowflake, Vertica | |
| NoSQL Database | As with relational databases, NoSQL databases may also be used as sources and targets for data lake information and in some cases, may even be used directly as storage mechanisms for the lake depending on desired performance characteristics. | ElasticSearch, MongoDB, Cassandra |
It is not necessary to implement each and every one of these technologies in order to have a working data lake, but understanding the full breadth of the required technology can help with planning and prioritization.
There are also vendors like Silectis that provide platforms implementing many of these elements of the data lake out of the box. Leveraging vendor platforms can accelerate implementation. The right choice for your organization depends on budget, skills available, and the level of urgency surrounding your implementation.
GETTING STARTED WITH YOUR DATA LAKE
The broad capabilities of data lakes and their ability to scale up or down more flexibly are appealing, but the complexity of the technology is daunting. There are a few things that you can do to get your efforts started and determine how best to move forward:
- Identify key analyses and use cases – Start with an understanding of what is driving analysis in your environment. The analytical priorities should flow into technical requirements for the data lake and inform the approach to implementation.
- Get educated – While this blog post provides a high-level view of data lake technology, you (or someone on your team) should do some independent research into successful architectural approaches and the specifics of key technologies.
- Start with the cloud – Unless there are regulatory constraints or other barriers that prevent, you should look to the cloud for the initial implementation of your data lake. There still may be on premise elements supporting your lake, but the investment required and complexity of implementation can be reduced by using the cloud.
- Experiment and pilot – Get some hands on experience before making any big decisions. Your team, perhaps supported by an external provider, should set up a limited scope pilot that allows you to gain a deeper understanding of the dynamics of building a data lake, the operational implications, and the technology risks. Focus on implementing a few key elements of the architecture starting with storage and compute and integrating data from a limited number of source.
CONCLUSIONS
Hopefully, this post in combination with Part 1 has provided you with at least a high-level understanding of data lakes and a jumping off point for further research. In future posts, we will address some of the technology in more detail and do a deeper dive into our platform Magpie.
FURTHER READING
Here are some additional resources that can help you get started:
- You can find Part 1 of this series here. It provides a higher-level definition of data lakes more focused on their basic capabilities.
- You can read more about how the dynamics of analytics are changing and how that impacts your architecture in our white paper Effective Insight Delivery.
If you would like a demonstration of the our platform, or some feedback on your approach to the data lake, feel free to reach out by filling out a contact form.
Learn more about our platform Magpie here.
Demetrios Kotsikopoulos is the CEO of Silectis.
You can find him on LinkedIn and Twitter.