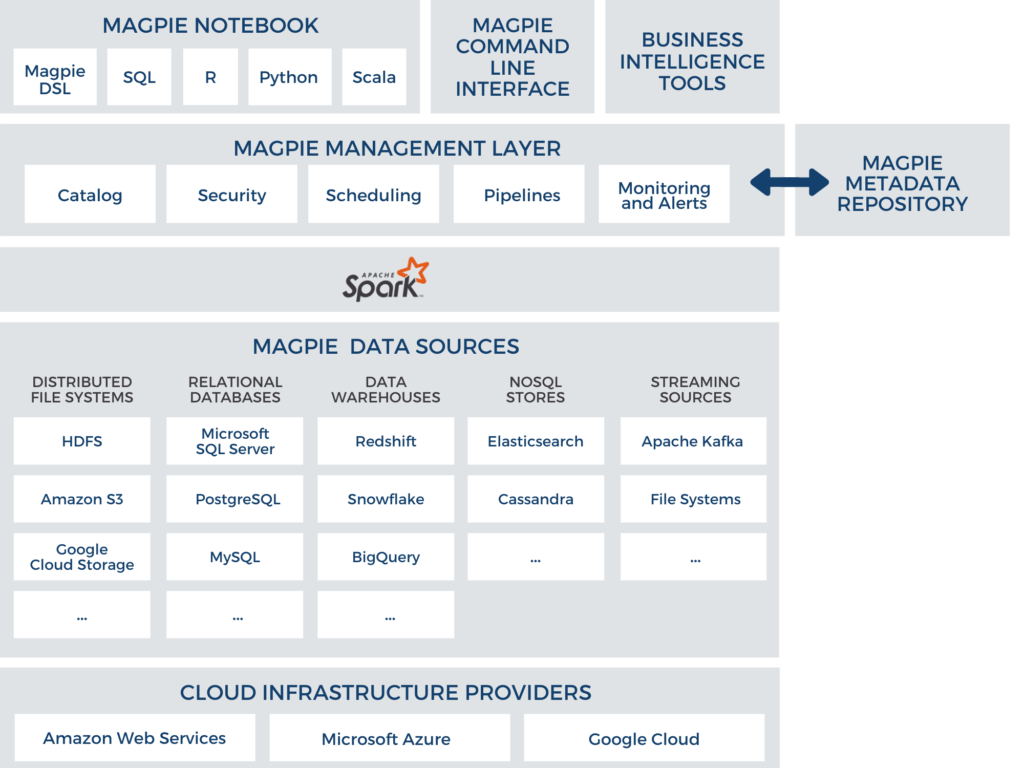
Built for data engineers
Magpie is a data engineering platform built to overcome the biggest challenges enterprises face in generating insight from their data.
Productivity >
Governance & Security >
Flexibility & Scale >
Operations >
Productivity
Enable a truly efficient data engineering function. With full lifecycle features built right into the platform, you’ll spend less time and resources on integrating tools and more time delivering results.
Rich Metadata Management
- Magpie’s built-in data catalog ensures that users have a single, consistent view of the data.
- Automated data exploration and profiling lets users quickly understand data and identify potential quality issues.
- Detailed activity capture, data lineage, and dependency tracking give users a richer understanding of enterprise data.
Integrated Tools
- Magpie reduces IT complexity by eliminating the need to use separate catalog, data exploration, and ETL tools.
- Engineers and analysts can be more productive by doing all of their work in one integrated environment.
The Languages You Know and Love
- No need to hire or train up engineers; Magpie supports SQL, Python, R, and Scala.
- Write less code and get your work done faster by leveraging Magpie’s built in capabilities to simplify and automate routine data engineering tasks.
Collaborative Notebook UI
- Analysts and engineers can document and share their activities in notebooks.
- Built in data visualizations ease communications across your team.
- Integrated with Github for revision control.
Governance & Security
Keeping your data safe is our priority. Integrated security and governance features let you keep control of your data while making accessible when and where it is needed.
Data Lineage
- Understand the provenance of your data.
- Track dependencies across tables.
- View history for all objects.
Detailed Activity Tracking
- Every action within Magpie is tracked giving you a comprehensive view of how the data is being accessed and by whom.
- Understand activity at the object, user, and organization level.
Object-Level Access Control
- Apply security at the repository, schema, or table level.
- Use a single role-based security model that spans data structures, data sources, data pipelines, and notebooks.
Flexibility & Scale
Spend less time worrying about growing data volumes and costs. Magpie scales to handle the toughest data engineering challenges while integrating seamlessly into your environment.
Enterprise-Grade Performance
- Leverage the full power and scalability of Spark’s open source ecosystem while benefiting from Magpie’s advanced data engineering tools.
- Use Spark’s advanced capabilities without all of the complexity of implementing Spark on your own.
- Magpie’s shared catalog, security, and collaboration capabilities let you add new team members and scale your processes.
Seamless Integration
- Deploy across AWS, Google Cloud, or Microsoft Azure.
- Access a broad range of data sources including S3, ADLS, Google Cloud Storage, relational databases, and analytics databases like Snowflake, Redshift, and BigQuery.
- Create custom integrations using Magpie’s built in programming languages to tap into any API.
Operations
Use Magpie’s built in capabilities and integrate with your existing processes to fully automate deployments and operations.
Orchestration & Scheduling
- Leverage Magpie’s built-in scheduling and dependency management or leverage external orchestration tools like Apache Airflow.
- Magpie provides comprehensive reporting on pipeline execution and real-time alerts when jobs fail.
DevOps Support
- Leverage the same scripts across Magpie’s notebook interface and command line interface while integrating with Github for revision control.
- Create isolated environments for development, QA, and production using Magpie’s built-in repository structure.
- Integrate with your existing CI/CD tools.
Ready to Unify Your Data Engineering Toolset? Get a Demo of Magpie.
Let us know a bit about yourself, and we’ll be in touch to set up a demo.