In this blog post, we’ll walk you through how data science and data engineering are complementary disciplines. We’ll also delineate a third category: data analysis. We’ll explore how both data engineering and data science should be marshaled to make better decisions.
Organizations often struggle to strike the right balance between engineering, analysis, and data science skills within data teams. To identify gaps in talent, resources, or tools, it is useful to conceptualize how data engineering and data science function within an organization.
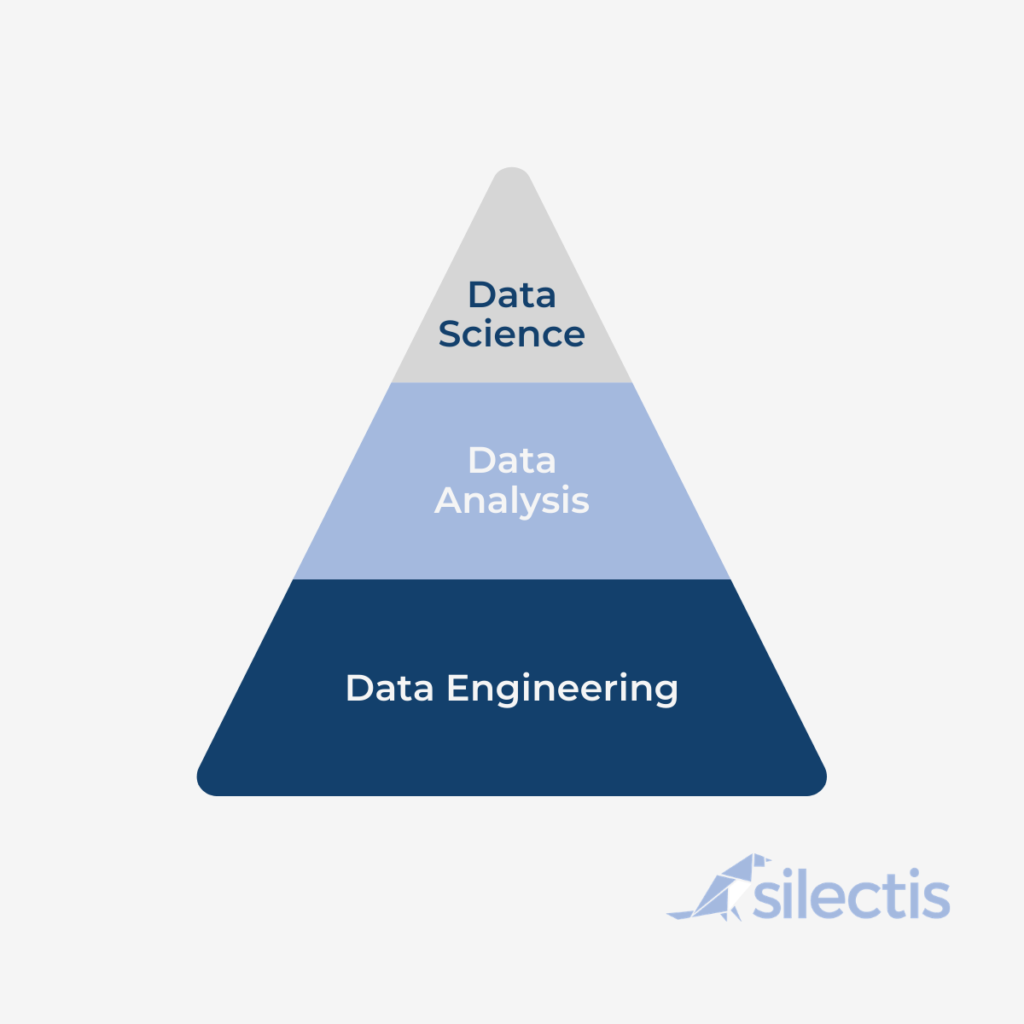
Articles with titles like “Data Science vs Data Engineering” often frame the relationship as two opposing disciplines. It is more accurate, however, to portray the relationship as a pyramid – where data engineering provides a foundation for data science. This post delineates how data science, data analytics, and data engineering build towards the ultimate goal of empowering data-driven decisions.
What is Data Science, Really?
When companies talk about data science, they are generally referring to drawing insights from data using analytical and machine learning (ML) techniques.
For a practice that largely deals with numbers, models, and algorithms, “data science” is quite a nebulous term. The term has been tossed around since the 1970s. However, the recognition of data science as its own discipline began in the early 00s. The phrase has become somewhat of an industry buzzword as many terms do when they skyrocket into popularity. Data science is sometimes used as an umbrella term meant to encompass all sorts of related topics, such as: data visualization, data wrangling, natural language processing, recommender systems, geospatial analysis, artificial intelligence, and so on.
We don’t necessarily need a rigid definition of data science to differentiate it from data analysis and data engineering. Here, when we say “data science,” we are simply talking about the methods, tools, and subdisciplines that extend analytics beyond historical descriptions (more on this below), towards deeper insights. Data science is exemplified by using predictive analytics and machine learning to make decisions. Said differently, data science is the practice of using historical data to predict future outcomes.
Defining Data Analysis
There is a distinction between data science and traditional data analysis. This is important to note because it is difficult to conduct meaningful data science without a foundation of data analysis.
Data analysis looks at patterns in data that have already occurred, as opposed to predicting some future outcome, as with predictive analytics, for example. Many industries have formalized data analysis in the form of Business Intelligence. Think of the slice and dice charts that you see visualized in tools like a Looker or Tableau dashboard. Whereas you cannot have effective data science without first analyzing data, organizations with business intelligence programs do not necessarily have mature data science programs. It typically just depends on business objectives.
Mind if we keep in touch?
We’ll occasionally share data engineering resources and best practices, Silectis news and events, and product updates. Just the good stuff — we promise.
So then what is Data Engineering?
Data engineering is the practice of integrating and organizing data to support decision-making (whether that’s through analysis or data science). Data engineering sits at the bottom of our pyramid, enabling both data analysis and data science. Data engineering has four components: exploring data, organizing data, governance and data management, and operationalizing data infrastructure.
Exploring and characterizing data is a fundamental first step in data engineering. Data engineers need to understand the semantics of the data in order to reshape the data for downstream use. This also naturally requires understanding the needs and objectives of the downstream stakeholders. For example, is this data intended for creating routine business reports? Deeper exploration by analysts? Esoteric modelling techniques by data scientists? These details will inform how data ought to be organized and served.
Getting data organized is how data engineering is commonly understood. From the point of extraction from source systems, data must be structured and logically organized before it can flow to the target environment. This entails building data pipelines or what is commonly known as ETL or ELT (extract, transform, load).
An often overlooked aspect of data engineering is ensuring that data has the proper governance and security around it. Data security has conventionally fallen to IT or Database Administrators. However, tables, pipelines, and automation utilized during ETL also demand security around data access as well as traceability. Thus, governance has become a key component of data engineering.
Finally, data engineering has increasingly demanded instrumenting cloud infrastructures and owning devops-like automation (sometimes known as ‘DataOps’). This becomes especially important when existing tools need to be scaled up to handle growing workloads.
Putting it All Together in the Pyramid
For data-driven organizations, the arrangement of data disciplines impacts everyone. Hopefully the above information gives you a good understanding of how data engineering informs or complements data analysis and data science, rather than competes with it. Reliable practices and tools across each of the stages of the pyramid will ultimately drive sound business decisions.
If you are looking for a better way to centralize data engineering at your organization, learn more about our holistic data engineering platform, Magpie, here.