In this installment of Silectis Technical Tutorials, we provide a step-by-step introduction to building a machine learning model in R using Apache Spark. This post is intended for R users who understand the basics of machine learning and have an interest in learning about Spark’s machine learning capabilities.
OVERVIEW – CLASSIFYING DOCUMENTS USING NAÏVE BAYES MODEL
This tutorial demonstrates how to easily build a Naïve Bayes model using Spark MLlib with R’s sparklyr package. Naïve Bayes models apply Bayes’ theorem of conditional probability as a method for classification. These models are often used for document classification, where each observation is a document and each feature is the frequency of a term in the document. Bayes models are very efficient as they require a single pass over the training data to compute the conditional probability between feature and label.
For documents, this example uses transcripts of presidential speeches with the goal of predicting the president that delivered the speech. While this particular example isn’t connected to a business use case, this methodology can be applied in many business contexts, such as classifying legal contracts, user reviews, or documentation.
The code in this tutorial is run in the Silectis data lake platform, Magpie. Magpie is a tool built on top of Apache Spark for organizing and getting value from data. With easy access to Spark ML, Magpie users can explore different model behavior and learn how to best tune them.
You can find the code from this blog post here.
GETTING TO KNOW THE DATA
This tutorial uses a public corpus of presidential speeches converted from raw text files into a tabular format for usability. The dataset is made up of speeches from four presidents: Barack Obama, Ronald Reagan, Lyndon B. Johnson, and Franklin D. Roosevelt. The data can be downloaded in csv format here. It’s a great dataset for text mining, NLP, and training text classifier models. The data has the following fields:
- president – President that delivered the speech. In predictive modeling, the value you want to predict is also known as the “label.”
- title – Title of speech.
- date – Date the speech was delivered.
- speech_text – The model will make predictions based on the processed text in this field (also called the “features” for modeling).
To get a sense of the data, have a look at some sample rows:
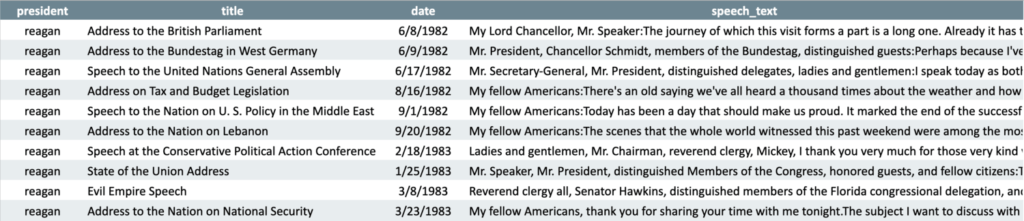
Before building machines learning models, thorough data exploration is highly recommended. Spending extra time characterizing a dataset can often lead to better predictive accuracy versus time spent tuning a black box model.
For this example, however, let’s just get a sense of the sample size and amount of text contained in the dataset.
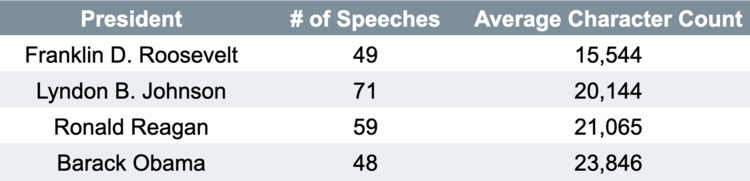
USING SPARKLYR IN SILECTIS MAGPIE
Start by telling Spark where to get the data.
Magpie allows users to run SQL queries against tables through the Magpie context. Think of the Magpie context as something similar to a Spark context.
Of course, if you are not yet a Magpie user, feel free to skip this section and get the data into your environment as a sparklyr dataframe however you see fit.
mc$defaultLibrary <- "sparklyr"
library(sparklyr)
library(tidyverse)
library(magpie)
speeches <- magpie::sql(
mc,
"SELECT president, speech_text FROM presidential_speeches"
)
Magpie supports SparkR and sparklyr libraries for interfacing with Apache Spark through R. First, we choose which Spark library we want to use by updating the variable: mc$defaultLibrary (mc is our Magpie context). This example will use sparklyr (more on that below).
Then, we load the libraries: sparklyr, tidyverse, and magpie. Learn more about the magpie library in the package documentation.
We can now query our speeches data by passing a SQL string to the Magpie context. We use sql() function from the magpie library which will return a sparklyr dataframe once we tell Spark to collect our data.
SPARKLYR MAKES BUILDING SPARK MACHINE LEARNING MODELS SIMPLE
One reason sparklyr has become the R user’s Spark-library-of-choice is that it supports using tidyverse functions for interacting with Spark dataframes. Users can manipulate Spark dataframes with familiar functions like group_by(), gather(), and mutate(). As demonstrated in the code below, users can also pass objects from function-to-function using the %>% pipe operator.
Another reason that sparklyr is so useful is because it provides wrappers for MLlib’s transformer, estimator, and pipeline functions that are extremely simple and neat, even by MLlib standards.
PREPROCESSING FOR TEXT MINING
Before we can train our Naïve Bayes model and classify some speeches, we will need to do some preprocessing on the data and convert the text to a format that is consumable by our model estimator. Our goal is to convert the raw text to an array of term frequencies.
Spark MLlib’s feature transformers are used to scale, convert, or modify features. MLlib’s feature transformers, of course, include widely used text mining methods. The code below applies the following feature transformer functions:
TOKENIZER
Tokenization breaks the speeches into individual words, e.g.,
“Each time we gather to inaugurate a President we bear witness to the enduring strength of our Constitution.”
[each, time, we, gather, to, inaugurate, a, president, we, bear, witness, to, the, enduring, strength, of, our, constitution]
STOP WORD REMOVER
Stop words are words which should be excluded from the input, typically because the words appear frequently and don’t carry as much meaning. The stop words remover drops all the stop words from the output of a tokenizer, e.g.,
[each, time, we, gather, to, inaugurate, a, president, we, bear, witness, to, the, enduring, strength, of, our, constitution]
[time, gather, inaugurate, president, bear, witness, enduring, strength, constitution]
TERM FREQUENCY HASHING
Finally, the term frequency hashing algorithm generates the relative frequency of our words across the documents. The output is a human-incomprehensible set of feature vectors that reflects the importance of a term across all the documents in the corpus.
The speech dataset is relatively small compared to some text mining datasets so we set the number of features equal to 2^12, a reduction from the default of 2^18 (this reduces the number of buckets in the hash table algorithm).
RANDOM SPLIT
After preprocessing, we finally split the data into training and testing partitions. 30% of the data is held out for testing the model’s predictions with the remaining 70% used for training the Naïve Bayes classifier. In this example, we use random sampling. However, thoughtfully sampling often can improve performance, especially for datasets that are small or asymmetrically distributed.
partitions <- speeches %>%
ft_tokenizer(input_col = 'speech_text', output_col = 'words') %>%
ft_stop_words_remover(input_col = 'words', output_col = 'clean_words') %>%
ft_hashing_tf(
input_col = 'clean_words',
output_col = 'words_vector',
num_features = 2^12
) %>%
sdf_random_split(training = 0.7, test = 0.3, seed = 416)
Users that are accustomed to building Spark ML models with Python or Scala will notice sparklyr simplifies assembling a final input vector and defining a Spark ML pipeline.
RUNNING THE MODEL
Believe it or not, the code above has not executed anything yet. Spark ML components are defined up front before actually manipulating data or training a model. Spark is “lazy” in that it doesn’t execute these commands until the end in order to minimize the computational overhead.
The Naïve Bayes model can finally be trained on the training data. This evaluates the Bayesian probability distributions for each term in the speech feature space.
Notice that sparklyr functions use the tilda symbol to assign the relationship between labels and features. This syntax is very common in R and should be familiar to any R user that has created a regression model with lm()
nb_model <- partitions$training %>%
ml_naive_bayes(president ~ words_vector)
With the model weights estimated, we can now make predictions against the test set.
pred <- ml_predict(nb_model, partitions$test)
To measure the success of this model, the Multiclass Classification Evaluator determines how often the model correctly predicted the president.
ml_multiclass_classification_evaluator(pred)
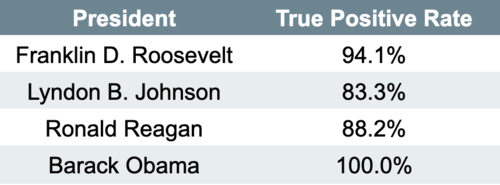
The model has an accuracy of 90.3%. Our modeling was fruitful! Here is a breakdown of the predictive accuracy for each president:
CONCLUSION
It looks like this machine learning model might be in danger of overfitting based on the 100% accuracy in predicting one of our labels. Overfitting would mean our model might not be able to generalize if, for instance, we added many new samples to our dataset. Potential next steps for this classification model are to test a smarter sampling method, hyperparameter tuning, a more thorough inspection of the feature vectors, and evaluating the model’s precision/recall.
Spark’s machine learning library is a very powerful tool for machine learning. This tutorial demonstrates the basics of using sparklyr’s simple syntax to build powerful machine learning models in Apache Spark.
Learn how to spend more time getting insight with Magpie; sign up for a demo.
Brendan Freehart is a Data Engineer at Silectis.
You can find him on LinkedIn.