In this blog post, we explore how a data analyst can know when to trust data and when to be skeptical. Using data integrity features in your modern data engineering platform should help you sort this quickly, and move on to empowering decision-making across the company.
DATA INTEGRITY: JUST THE FACTS
People say you can trust data. “Let the data speak for itself” or “the data doesn’t lie.” Famous television personalities ask for “just the facts, ma’am.” But where did these facts (or data) come from? Who made them? And how do we know there are no inherent data integrity issues?
Data is some sort of measurement of an event or an object. When a data analyst begins working with a data set, the analyst usually has a rough idea of the dataset, but this is given by descriptive information, often in a text summary of the dataset. Only after an analyst begins his or her analysis does it become clear what is actually going on in the data set.
This is often too late.
HOW TO ANALYZE DATA BEFORE ANALYSIS
In practice, an issue of data integrity or trust is tripped across because an analyst started some thread of predictable analysis to test out the data. An anomaly might be highlighted by joining in some other data that should produce a simple result, and finding that the join didn’t make sense. Or when plotting a result of a query, one finds that expected local information lands on the wrong side of the globe. Once a mistake is made, the analyst then needs to start to dig into the information to figure out what went wrong. Is the data bad? Are half the points incorrect? Is the measurement bad? Is the device creating the data causing an error? Are outliers completely skewing the resultant analysis? Was it written down or entered incorrectly? Tracing this error back is a significant roadblock to progress. Productivity has to stop until the issue is sorted out.
How can we look at data and attempt to get an idea of quality and integrity before analysis begins?
At Silectis, we rely heavily on the “Profile” function, which is a key piece of our Magpie platform. This function was highlighted in depth in a recent posting on NYC taxi and for hire vehicle data and in a posting on how Magpie allows a user to supercharge data exploration. These two blogs dig deeply into Magpie’s ability to break open a data set before the analysis takes place, naturally avoiding the false starts that are typical of analysts who are not using Magpie, and are thus forced to find data anomalies at a time that is very disruptive to their analysis.
To illustrate the value of Magpie’s profile ability when trying to asses the likely validity of a data set, the below snapshots show two different sets of data. Both are contained in the NYC Taxi dataset that we used in a previous post. And both of them can be assessed before any analysis takes place. This capability not only tells a data scientist or analyst what to expect, but allows for confidence in the data itself.
DATA PROFILING FOR DATA INTEGRITY
NYC’s Taxi and Limousine Commission (TLC) has made a huge collection of Trip Record Data available to the public through NYC’s Open Data initiative. This data goes back to 2009, and includes trip data from a variety of sources. The data is in a .csv format and is broken into 36 different files per each calendar year. The data is created by trip record submissions made by the various entities regulated by the TLC. The information contains multiple fields, but for the purposes of this demonstration, we will focus on fare data and tip data for a year’s worth of data spanning 2017 and 2018.
In this blog post, we will show graphs of fare data and tip data. Magpie’s profile ability will make it clear that some of the taxi data is human created and some is machine generated. We don’t really know how this information is captured, but maybe we can assume that all the fare information is machine generated data from the internal taxi systems. We could also assume that the tip data is similarly recorded. But we’d probably be wrong…
TAXI FARE DATA
For a clear example of machine generated data, let’s look at the fare data:
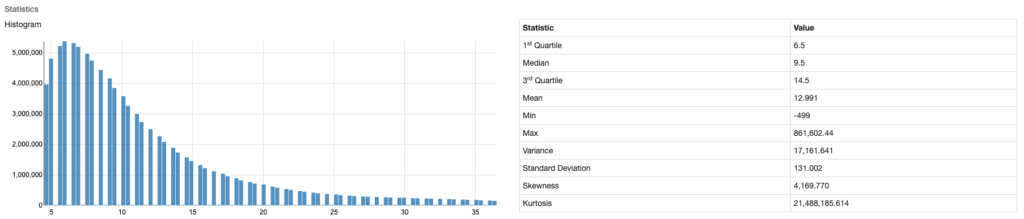
Magpie’s profile capability runs on the entire taxi data set but kicks out the above graph for just the taxi fare data. Immediately it becomes clear to an observer that the data set is likely machine generated, and there is a predictable increment by which the fares increase over time, as shown by the way the bars are grouped into sets of 2. If any of our readers have been in a taxi in NYC, this is immediately recognizable, as the fares do increase in $0.50 increments (https://www1.nyc.gov/site/tlc/passengers/taxi-fare.page), and this is visible in the graph. And then, it is clear there is some normality to the distribution of the data over time. In this case, the frequency of taxi rides over a certain distance taper off in a pattern. There are no outliers, and everything seems to be fine with the data. The curve is even a pleasant example of predictability. This is clearly a clean dataset that is created by a machine. An analyst can confidently begin working with this data, knowing that it likely represents exactly what it is designed to capture: taxi fares.
TAXI TIP DATA
Now, on to another quite similar piece of information that is so close to the taxi fare data, but fraught with issues: taxi driver tips. Using Magpie’s profile, here is what the data looks like:
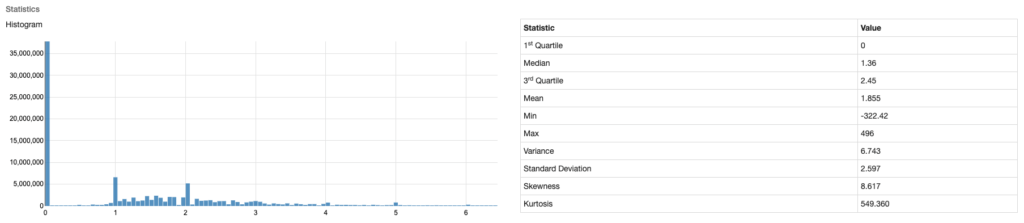
Immediately, it becomes clear to an observer that this data is unpredictable at best. There are a few lumps at single dollar intervals, which makes sense for cash tips (and lazy riders who are not aspiring mathematicians). But what else can we infer? The giant “$0” tip starts to lead the analyst down another path of hypothetical reasoning. What type of data is this? How is it generated? With a distribution like this, we have to start thinking a bit more about how our data was created, and if we can trust it. This data is to be at least partly machine generated by a credit card reader (where the rider can punch in numerical digits for a tip), but plenty of this information is going to be manually entered by the driver as cash is handed over. This theory is backed up by the relatively large spikes at $1 and $2. But back to that big $0 mark. Are riders really not tipping? or can the analyst assume that some of this information is inaccurate as the driver could even be rounding up, or …gasp… not reporting cash tips.
These two data sets give a picture of the exact same moment in a taxi ride, however the data they contain is very different. One can be trusted, one cannot. Using Magpie, an analyst can easily see these differences and begin to plan ahead so he or she is not tripped up by a revelation that the data might actually lie.
Read our latest white paper on operationalizing your analytics.